在 Agentic AI 的各式應用場景中,提供正確且良好品質的上下文來源是至關重要的環結,實務上我們可能透過 RAG 從外部檢索資料,或是從手邊的各種檔案格式轉換成 markdown 來提供 LLM 作為上下文參考資料以便展開執行後續的任務,若以輕量、快速上手為考量,可以試試 MarkItDown,但若只能在純地端環境執行,或是對於文件內容(例如:表格、版面)有更高的解析需求不妨試試 Docling,本文以實務角度比較兩者設計取向、支援格式與優缺點,以及提供不同應用場景的建議。
在建立知識庫、資料前處理或把企業文件提供給 LLM 時,原始文件往往可能是 PDF、各種 Office 文件格式、圖片或音訊,而真正要給 LLM 使用時,需要:
- 保留語意與結構(標題、段落、表格…等)。
- 去除雜訊並以 token 使用效率高的格式呈現(例如:Markdown)。
- 在有需要時,保留更結構化的表示(例如:JSON)以便後續自動化處理。
MarkItDown 與 Docling 都致力於把各種來源轉成容易被 LLM 或檢索系統消化的輸出,但設計側重與功能集合有明顯差異,下面我們直接比較。
MarkItDown
- 出處:由 Microsoft AutoGen 團隊維護(Python)。
- 設計取向:把各式檔案轉成「結構化 Markdown」;以 LLM 與文本分析為取向。
- 優勢:
- 直接產生適合 LLM 的 Markdown(標題、列表、表格、內嵌程式碼等)。
- 支援多媒體(圖片 OCR、音訊轉錄、YouTube 字幕抓取)。
- 可用作 MCP 伺服器,利於 AI Agent/LLM 整合。
- 限制:
- 對於複雜的 PDF 版面(精細表格、多欄佈局、複雜閱讀順序),解析深度稍嫌不足。
- 若要取得更高階 PDF 能力,可能會依賴 Azure Document Intelligence(雲端)。
若要使用 MarkItDown MCP 現在可以在 GitHub MCP Registry(https://github.com/mcp) 列表找到,也可以 docker 方式或 clone 整個專案在本地端以 STDIO 的方式執行,參考微軟官方 GitHub 說明。
Docling
- 出處:由 Docling Project(原起始於 IBM Research Zurich,目前管於 LF AI & Data)維護。
- 設計取向:專注於文件理解,特別是進階 PDF 解析(版面、閱讀順序、表格結構、公式、程式碼、影像分類),並提供統一的 DoclingDocument 表示與多種匯出選項。
- 優勢:
- 在複雜 PDF(掃描文件、排版、多欄表格)與表格重構上表現優異,使用自家模型(DocLayNet、TableFormer)提升解析品質。
- 支援本地執行(適合敏感資料或隔離環境),也有 VLM / ASR 整合能力。
- 輸出豐富:Markdown / HTML / JSON / DocTags 等,便於後續分析或顯示詳細資訊。
- 與 LangChain、LlamaIndex、Haystack 等生態系可以直接整合,便於搭建 RAG pipeline。
- 限制:
- 因為功能較廣、選項較多,學習曲線會比 MarkItDown 高。
- Docling 會完全在本地環境執行,需要考量相關系統資源 (是優點也是缺點)。
如何取得並建置 Docling 環境可以參考 GitHub 專案,它一樣有支援 MCP 但要在它的官網才找得到說明,如同前面說的,它是完全在本地端執行,所以 MCP 是由 uvx 來執行啟動。
如果想要手動在 mcp.json 加入這兩個 MCP 工具,可以直接參考:
1 | { |
支援格式與各面向比較
| 格式 | MarkItDown | Docling | 備註 |
|---|---|---|---|
| 良好 | 優秀(尤其是複雜/掃描文件) | MarkItDown 對一般 PDF 處理良好;若需高保真解析或掃描 OCR 建議用 Docling | |
| DOCX / PPTX / XLSX | 支援 | 支援 | 兩者皆可處理 Office 文件 |
| Images | OCR、EXIF 支援 | OCR + VLM(視覺語言模型)分類支援 | Docling 在影像分類與 VLM 整合上較強 |
| Audio (WAV / MP3) | 支援音訊轉錄 | ASR 支援 | 兩者皆支援轉錄;可串接不同模型以改善品質 |
| HTML | 支援 | 支援 | 皆可匯入網頁內容 |
| Markdown | 原生支援 | 支援匯入/匯出 | |
| CSV / JSON / XML | 文字格式支援 | 支援 | 適合結構化文字資料 |
| YouTube | 可抓取與轉錄 | 可處理 WebVTT / 影片字幕 | MarkItDown 偏向抓取與轉錄;Docling 處理字幕檔更完整 |
| EPUB / ZIP | 支援 | 支援 | 支援程度依內容與封裝方式而異 |
| VTT / WebVTT | 支援 | 支援 | 若以字幕為主,Docling 支援度較好 |
-
設計目標:
- MarkItDown:以「快速把各類來源轉成 LLM-friendly Markdown」為核心,偏重 token 效率與多媒體前處理。
- Docling:以「高保真文件理解」為核心,強調版面/表格/閱讀順序的精確還原與 lossless 結構化。
-
解析深度與還原度:
- MarkItDown:輸出以可讀且可索引的 Markdown 為主,對一般文件足夠;遇到跨欄或複雜表格時可能會犧牲部分細節。
- Docling:使用版面模型與表格重建,保留更多區塊座標與結構資訊,適合需精準抽取或重現原始排版的情境。
-
多媒體支援:
- MarkItDown:支援音訊轉錄、YouTube 字幕抓取、圖片 OCR 等,偏向 LLM 前處理工作流。
- Docling:也支援 OCR/ASR/VLM,但更強調影像分類、表格語意重構與公式/程式碼片段的解析。
-
本地化 vs 雲端依賴:
- MarkItDown:可本地執行,但在某些高階 PDF 能力上會建議採用雲端 Azure Document Intelligence 作為選項。
- Docling:設計上強調本地端運行,適合敏感資料或離線環境。
-
效能與資源需求:
- MarkItDown:輕量、上手快,適合大量快速預處理。
- Docling:依賴模型與較高運算資源,單檔處理時間較長但輸出更精確。
-
整合生態與可擴充性:
- MarkItDown:以 plugin 與 MCP 為導向,容易接入 AI Agent / LLM pipeline。
- Docling:提供豐富的 JSON / Markdown / HTML 匯出,與 LangChain、LlamaIndex 等檢索生態整合良好,利於深度資料工程。
-
可驗證性與審核:
- MarkItDown:輸出簡潔,人工檢視方便,但在表格或版面細節需抽樣驗證。
- Docling:提供中間結構(座標、區塊、表格邊界),便於自動化驗證與回溯修正。
-
學習曲線與運維成本:
- MarkItDown:學習低、文件少、運維簡單。
- Docling:功能與選項多,需時間調校模型與處理參數,運維成本較高。
總結
MarkItDown 與 Docling 均可將各類原始文件轉為 LLM 友好的結構化格式,但設計取向與適用場景不同:MarkItDown 輕量且易上手,輸出以節省 token 的 Markdown 為主,適合大量快速預處理與整合至 AI Agent / LLM pipeline;Docling 則強調高保真文件理解與版面還原,擅長複雜 PDF、表格重建及本地化運行,適用於需精準解析或資安敏感的情境。實務上如果是遇到比較複雜的文件內容,例如像論文有分左右兩欄、各式表格,或是有圖片需要 OCR 辨識、流程圖想要轉換成 Mermaid,使用 Docling 產出的結果都蠻不錯的,強力推薦給大家!
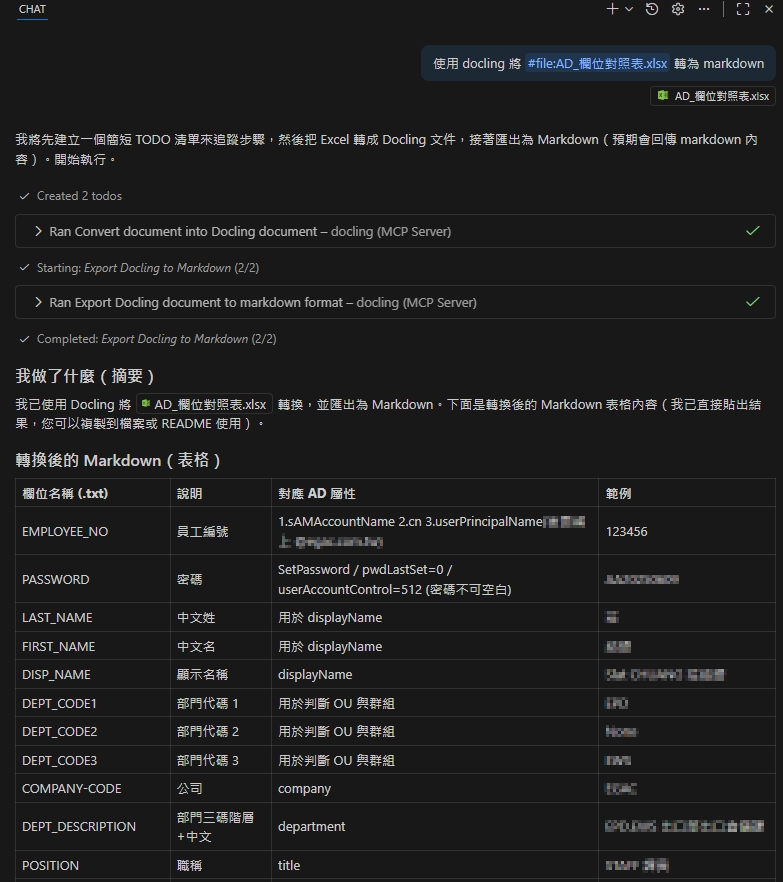
.xls -> .md
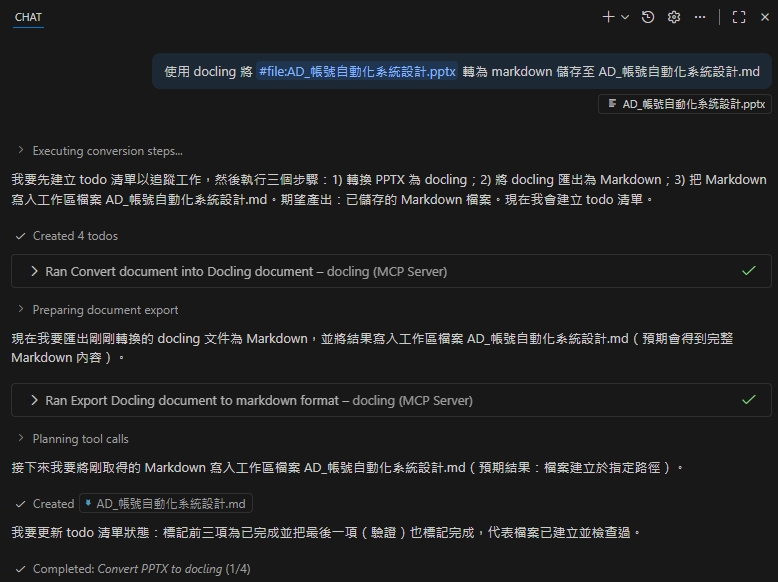
.pptx -> .md
使用本地端資源運行 Docling